
¿Cómo se miden los datos del coronavirus?
- Las matemáticas nos están ayudando a dar certezas en un mar de incertidumbre pandémica
- Analizamos las herramientas matemáticas que se usan para medir los datos de la pandemia de coronavirus
- Coronavirus: última hora en directo | Más información en RTVE.es/ciencia


- Santi García Cremades es matemático y profesor de la Universidad Miguel Hernández
- El Método es un programa de divulgación científica en torno al coronavirus
- Más ciencia en rtve.es/ciencia
Desde febrero de 2020, las matemáticas abren los informativos, son portada de los periódicos y están en boca de todos, mascarillas mediante. Lo nunca visto, vaya. El coronavirus ha puesto a la ciencia de datos en la línea de fuego del interés general. Nos hemos acostumbrado a escuchar expresiones como “los datos crecen de forma exponencial”, “viene una nueva ola”, “hemos conseguido aplanar la curva”, etc. Está claro, esta maldita enfermedad, la COVID-19, ha convertido a la estadística en algo mediático. Medir los números que tanto nos duelen se vuelve imprescindible. Las medidas políticas se basan en ellos, igual que las decisiones sanitarias, y hasta nuestro estado mental cambia en función de las cifras del coronavirus.
Las matemáticas nos están ayudando a dar certezas en un mar de incertidumbre pandémica. Medir es algo tan antiguo como el contar, y como el escribir. Que el arte de medir esté con el Homo sapiens civilizado desde casi siempre no quiere decir que sea un problema resuelto. De hecho, “cálculo” significa en latín “piedrecita”, concretamente la típica china que se te mete en el zapato y te hace parecer que bailas swing en la calle al quitártela. Sí, calcular el mundo que nos rodea es algo incómodo, por su imperfección.
Las matemáticas son teóricas, viven en el mundo de lo abstracto, y cuando son aplicadas nunca cuadran las cuentas al 100%. Les pasó a los pitagóricos al intentar calcular el número Pi de forma exacta, le pasó al mismísimo Newton al intentar calcular el área bajo una curva, y nos pasa ahora al intentar entender y predecir los datos de esta maldita pandemia.
¿Qué herramientas matemáticas se usan para medir los datos de una pandemia?
Centrémonos en el coronavirus, que es el tema que nos toca por todos los poros. Las herramientas matemáticas para estudiar una epidemia son muy variadas y diferentes en su naturaleza. Son tiempos para que todos arrimemos el hombro, cada uno según su clavícula y escápula. En la ciencia más exacta hay familias, como si fuera esto Harry Potter:
Los de álgebra, acostumbrados a trabajar entes abstractos e intangibles, aportan su sabiduría en ecuaciones y buscan la fórmula que más se ajuste a la evolución de las curvas de datos. Cuando oyen hablar de crecimiento exponencial, se echan las manos a la cabeza. Ninguna función simple crece más rápido que la función exponencial, y si en algún momento hemos tenido curvas creciendo exponencialmente, no han durado más de una semana.
Los de análisis, acostumbrados a calcular cualquier variable que cambie en el tiempo, darán uno de los conceptos más relevantes: la variación. Si alguien sabe decir cuándo viene una ola, son ellos. Aportarán las benditas derivadas con las que podemos entender los cambios de tendencia, los máximos, los mínimos y, lo más importante, las variaciones entre poblaciones (lo que dará lugar al modelo más famoso en epidemiología: el modelo SIR).
Los de geometría, acostumbrados a valorar las figuras por su estructura y su curvatura, trabajan más en la parte microbiológica, pero nos darán conceptos importantes para el aplanamiento o no de la curva.
Hay más familias, pero vamos a quedarnos con estas tres. Por supuesto, de todo esto beben el resto de áreas y ciencias. La estadística es la más importante de todas, pues se basa en el control de la incertidumbre.
La estadística para medir el coronavirus
Cabe destacar que hablar de estadística no es dar datos sueltos y ya está, dar porcentajes o hablar de números del coronavirus sin un contexto es como decir palabras sin crear una oración con sentido. Si tenemos que plantear en qué momento estamos de la pandemia hay dos preguntas fundamentales: ¿qué variable nos da la información y cómo evoluciona esa variable? La primera pregunta era importantísima desde el principio y ha sido un gran problema. Nos interesa saber la variable “número de contagios”, parece evidente, pero ¿cómo medimos los contagios cuando el virus es desconocido?
En febrero arrancó la primera ola en Asia y Europa, poco después en el resto del mundo. Pero en marzo no teníamos la capacidad de detección suficiente para saber el verdadero número de personas infectadas. Por tanto, en la primera ola, la curva más usada no fue la de contagios, sino la de hospitalizados y fallecidos. Pero ni siquiera en la forma de contar fallecidos por COVID-19 había consenso entre países. La detección no es completa, nunca lo es en el mundo real, y el número real de fallecidos causados por esta enfermedad sigue estando bajo estudio. Pero eso no quita que no podamos estudiar la evolución de las cifras. Ahí fue cuando los modelos matemáticos entraron en acción.
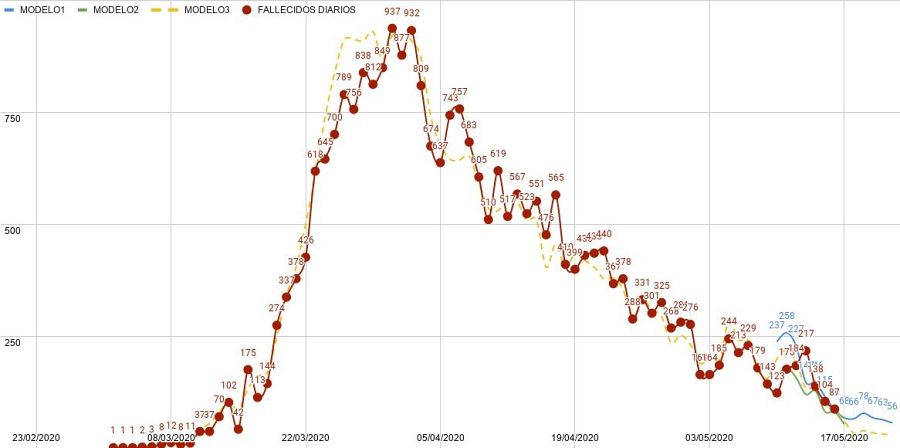
Serie temporal sobre los fallecidos por COVID-19 en España. Fuente: Santi García Cremades.
¿Qué modelos usar para medir la epidemia del coronavirus?
El modelo SIR fue el primero en levantar la mano, por razones evidentes, es el modelo que distribuye una población en tres categorías: Susceptibles, Infectados y Recuperados. Fácil, ¿no? Es un modelo basado en ecuaciones con derivadas, propuesto en 1926 por el escocés Anderson Gray McKendrick para estudiar la malaria. Desde entonces, cualquier estudio epidemiológico se basa en este modelo y un valor en concreto: el factor reproductivo del virus (conocido como Rt). Este parámetro indica la dinámica de la enfermedad y se considera la existencia de un brote cuando el valor es mayor que 1. En ese momento, la epidemia es susceptible de control. El ISCIII publica este factor a diario y, en esta nueva ola, tenemos el factor reproductivo menor que 1 desde el 2 de noviembre de 2020.
Hay muchas variantes, siendo el modelo SEIR (con la E de Expuestos) el más presente, donde se puede analizar a nivel teórico los efectos de las medidas restrictivas en el resto de variables. Este modelo tiene el problema evidente que si no tienes una buena estimación de los infectados (la población I), no obtenemos la información más relevante: cuánta gente puede estar inmunizada.
Puesto que en tiempo real el modelo SIR parecía tener sus debilidades, salieron de golpe todos los modelos matemáticos que podía aportar cada familia. Podríamos destacar tres grandes categorías: las cadenas de Markov, las series temporales, y el machine learning.
Las cadenas de Markov tienen origen a principios del siglo XX, dentro de la teoría de la probabilidad. El nombre viene de Andrei Markov cuyo interés al crear las cadenas no tenía conexión con ningún fin práctico, salvo en otra de sus pasiones: la poesía. Es un método basado en probabilidades pasadas, para ponderar la probabilidad de un evento en el presente o futuro. Es un método muy aplicado para realizar predicciones como en meteorología, los buscadores de internet como Google o, claro está, en epidemias.
“no hace falta que nos hagan restricciones, sino entender la situación estadística“
Las series temporales se explican por sí mismas: son series de datos en un intervalo de tiempo. Podemos marcar el comienzo del uso de estas técnicas en los años 20 del siglo XX, con George Udny Yule y con el crack del 29, donde saber cómo evoluciona una variable que se ve afectada por cientos de ellas tomó una gran importancia en economía (cuando empezaría la econometría). En estos modelos se pueden aplicar decenas de versiones: aditivos, multiplicativos, autorregresivos, con distintas frecuencias, etc. Esta ha sido la base del modelo que utilicé para predecir la curva de fallecidos de abril a mediados de mayo, con mejor aproximación que el resto de métodos.

El machine learning es la herramienta más reciente y la menos matemática. Aunque Geoffrey Hinton introdujera el concepto en 1986, la aplicación y desarrollo han sido posteriores. Hay multitud de métodos, todos basados en el aprendizaje de una máquina a partir de un entrenamiento, es decir, de datos pasados.
Predicciones para controlar la COVID-19
Con todos estos modelos, nos encontramos con distintas predicciones, cada una con un error distinto. Al menos ya sabemos qué medir, tenemos la famosa Incidencia Acumulada, que es el número de casos de los últimos 14 días por 100 mil habitantes. El hecho de contar 14 días sirve para poder reducir el ruido diario en los datos. Es sencillo, imagina que queremos comparar cuánta comida comemos en distintas etapas. De forma diaria, un día te pegas el atracón y te saldrá un dato disparado con respecto al día que comiste menos. Sin embargo, si comparas la comida de dos semanas enteras con otras dos semanas, las diferencias son mínimas, más suaves.
El Instituto de Salud Global de Harvard recomienda el uso de la Incidencia Acumulada desde el 1 de julio de 2020, para tener datos que se puedan comparar entre poblaciones (para algo está la densidad) y donde se pueda ver la evolución suavizada sin demasiada variabilidad.
Estamos viendo que la curva actual es más estable, más fácil de estudiar y, por tanto, más fácil para tomar decisiones en función de datos fiables. Estamos bajando, sí, no tan rápido como nos gustaría, pero también tenemos que ser conscientes de la situación que vamos a tener en Navidad, para eso no hace falta que nos hagan restricciones, sino entender la situación estadística.
Para eso están las Matemáticas, para ayudarnos a todos. A nivel individual, para ser libre de engaños, para entender qué está ocurriendo de una forma independiente. A nivel global, para dar información, para evaluar medidas, para salvar vidas, al fin y al cabo.
Serie temporal sobre los fallecidos por COVID-19 en España. Fuente: Santi García Cremades